There is a lot of talk about bias in AI and how it results in bad and sometimes even harmful answers. But if you peel back a layer, the picture becomes more nuanced. In fact, without any bias, AI systems are useless and produce only random results when asked to produce new outputs. So the question really is which biases are the ones we want to keep and which ones we want to remove.
What exactly is Bias?
By now there are plenty of examples of bias in AIs: there are the classic examples were we know immediately that it’s bad and also where it likely comes from, for example nurses being depicted as female vs the doctor being a man. That is clearly an issue stemming from historical and hence outdated training examples. But there are also examples of AI acting overly optimistic or rigid, where the origin is less obvious. And then there are more technical bias examples such as an AI focusing more on the beginning and the end of a prompt - which seems to match human laziness - but is even less clear to explain technically.
But there are also biases that we are willing to accepted: we would be surprised if an AI generated a picture of a Nazi showing a person having a dark skin color of if an AI assumed elephants with 5 legs are totally fine. Those are biases, too, but somehow we are ok with them.
Where does Bias come from?
Bias comes from some sort of limitation: either limited flexibility/resources or limited time. At first glance, this sounds similar to humans using bias to avoid having to process every situation as a completely new perception but relying on past experiences to short cut decisions. In the case of AI it is less about being fast and saving resources, but more about constraints that were built-in during training.
Let’s dive a bit deeper to understand how this happens – and why it is needed. From machine learning theory – and if we call it AI or not, all the methods used to build and train modern AI systems are founded in machine learning – we know there are different types of bias: the way we find (or “train”) a model injects a bias. But also, the types of models we consider causes bias. And finally, the data we use for training presents a bias. Machine Learning theory also tells us that some sort of bias during learning is needed in order for a model to “generalize”, which essentially means: produce output also for cases that are not present exactly in the training data – otherwise our model would just memorize all of the training data and be unable to present an output for something not seen before. There is a theory behind that, of course, but it’s easy to illustrate the underlying principle so the idea behind that theory becomes clearer.
Let’s assume we have a very simple problem: based on some input values we want to predict output values. Figure 1 shows a couple of training points: the horizontal axis are the inputs; the vertical axis shows the outputs.
 Figure 1. A simple example of training data.
Figure 1. A simple example of training data.
We now want to train a model that helps us predict outputs also in-between (or to the left/right of) the data points we had available during training. A classic regression problem, right? The natural instinct is to draw a straight line and use that as “model”: see Figure 2. That seems to be the only one and best solution.
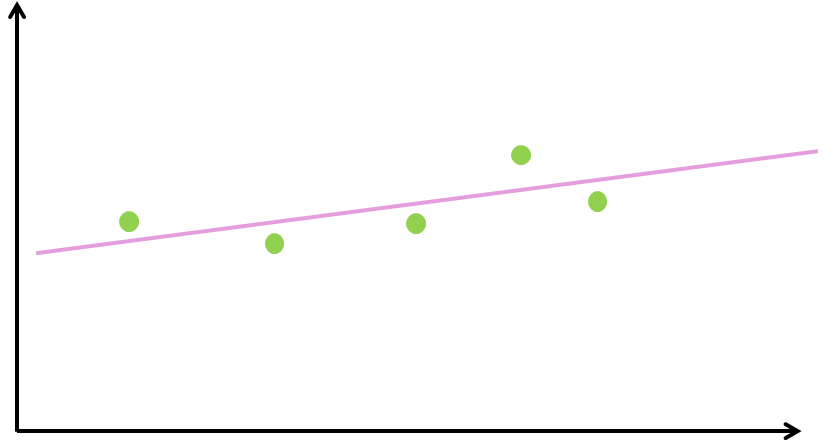 Figure 2. An intuitive and simple model.
Figure 2. An intuitive and simple model.
But by doing this, we have already injected a bias: we have limited the types of models we can use (only a straight line). Figure 3 shows two examples for models that come from a different family: and as we can see, they do fit the training data even better, but they also produce widely different predictions for points that aren’t exactly our training data points. Clearly the choice of model influences heavily what kind of generalizations are possible. We call this “model bias”.
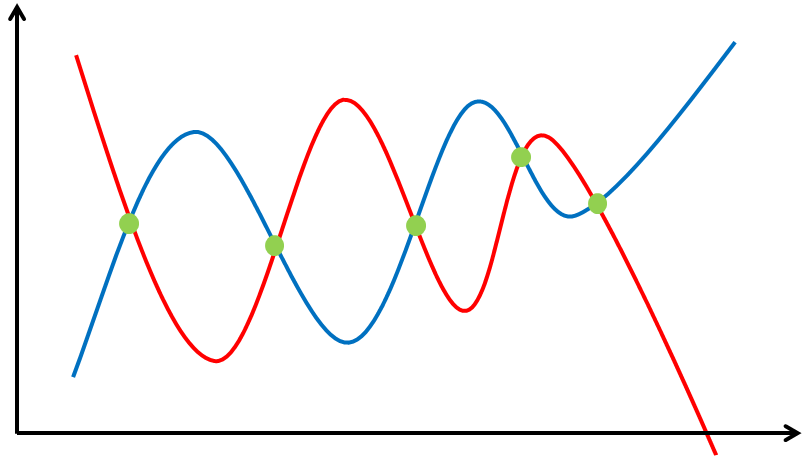 Figure 3. Two more complex models.
Figure 3. Two more complex models.
Figure 4 shows how the way we train the model injects another bias (the “algorithmic bias”). We go back to the model being a straight line. We can now put that line nicely in the middle of the data points (as we have seen in Figure 2), we can align it with the first and last data point (pink line in Figure 4), or we can fix it to the middle data point and adjust the angle so it fits the rest (dashed line in Figure 4). And there are many other - more or less intuitive - ways we can fit a line to a series of points. Also those choices result in rather different generalizations.
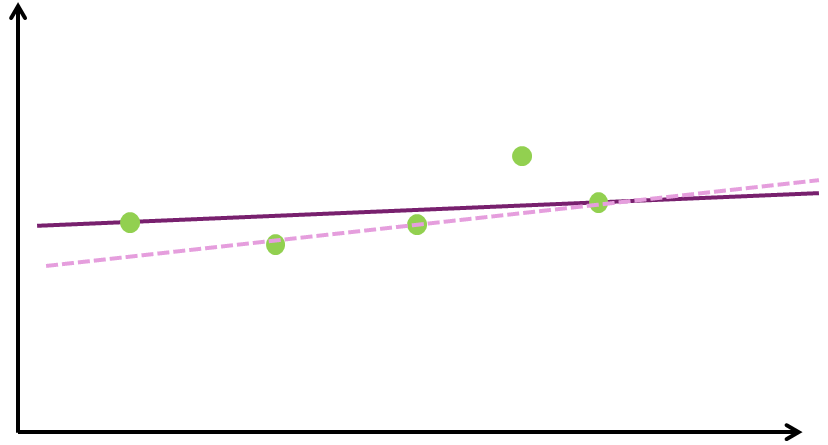 Figure 4. Different options to fit the simple model.
Figure 4. Different options to fit the simple model.
And finally, we have the “data bias”. Figure 5 illustrates that. If we ignore the yellow points in our graph, our line will look pretty different from the output where we included all the data. It sounds obvious but in reality it is actually not trivial to make sure the data does represent everything we want to model. One extreme case of this is no data at all which will result in completely random behavior – our model is not influenced by any actual knowledge. The other extreme is that we do have all variations of data points in our training data: elephants with 5 legs, purple elephants, … That’s a data set that provides zero information as well. On an interesting side note: Machine Learning theory has an underlying theorem claiming that the data sufficiently represents the reality we want to model. A data bias essentially means that this is not the case.
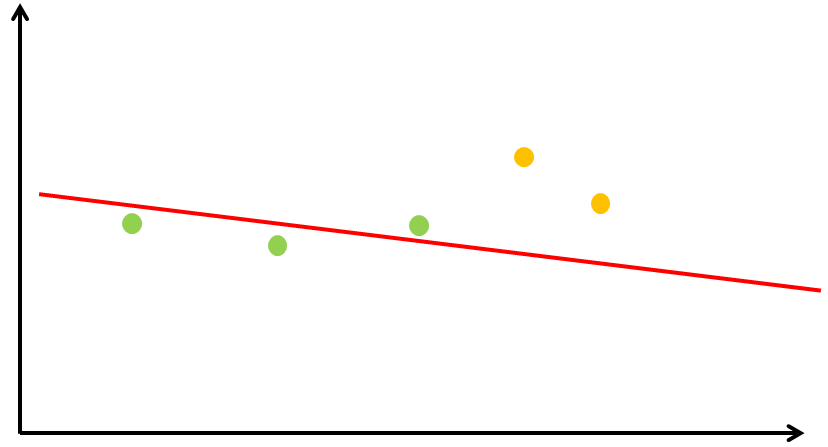 Figure 5. A different model, trained on only a part of the data.
Figure 5. A different model, trained on only a part of the data.
What we have tried to demonstrate here using a simple example is what Machine Learning Theory also proves: without any bias, our model will not generalize meaningfully, but it will just produce random noise. We need bias to learn. Which leads to an interesting philosophical discussion around what kind of bias humans use to learn - but that is outside the scope of this article.
Most often, the “data bias” is used as an explanation for bias in AI. In the (luckily: increasingly distant) past, it was more likely for nurses to be female and doctors to be male. Nazis were primarily white men. And elephants have four legs. These likelihoods are reflected in the training data and since an AI learns from that data, it will reflect this likelihood also in its answers. It has no way of knowing which of those biases are ok to have and which ones are unwanted.
Model and Algorithm Bias are less prominently discussed when we talk about modern AI models, but they are absolutely worth keeping in mind as well. Typical large scale AI models have billions of parameters and hence very little model bias, coupled with a training algorithm that is usually optimized for a numerical and not semantical goal. As seen above, this results in quite some flexibility how the model will generalize. This explains some of the bizarre hallucinations, where the answer certainly feels like the AI just threw a dice. In the end the output is the result of a model that picked a pretty random fit in an otherwise underspecified space. There are techniques to reduce the impact of the lack of biases around models and training algorithms, but that is a more technical topic and does not concern us here.
Can we fix unwanted Data Bias?
It should be easy to fix at least the bias in the data, right? Data that is completely from the past, like in the Nazi example, should remain untouched. The obvious ground truth bias (elephants have four legs) also remains. But a bias that is unwanted and carries into today needs updating, such as the one about male/female nurses/doctors. But it is not that easy. Should we also fix our AI so that it doesn’t assume dictators are more likely to be men? Should we remove the bias that elephants are gray (there are albinos, after all)? Many biases are actually very useful to avoid producing outcomes that are completely outside of reality or just plain strange. A herd of elephants with half albinos just does not make sense.
But even if we do identify all unwanted biases an AI has – which is a big if! - those are not always easy to fix. Some gender issues can probably be addressed by adding artificial training data that talks about opposite genders in historically biased roles (more female doctor and male nurse mentions, for example). But others are a lot harder to create or fix. For example: a big reason why AIs tend to be overly optimistic and convinced is that most material that is published is talking about positive results. Take scientific publications: there are hardly any papers about failed experiments – although arguably scientists spend the majority of their time on experiments that do fail. But scientists do not get tenure or research grants for publications about negative results – they need to publish positive, new outcomes. That could be changed, but it will not change the massively biased scientific publication base that AIs are currently trained on. An AI trained on the current publication body will learn that pretty much all experiments succeed.
What’s Next?
In short: AI needs bias to learn. Much of this bias simply describes how our world works and makes it possible to generalize meaningfully by staying within those boundaries. However, some of the biases are unwanted and need to be addressed – but detecting those biases is not always easy and compensating for those biases is often even harder. A human, who never left the UK, will be exposed to lots of information about villains with a thick German accent. But if that person is just little open-minded, there is plenty of other material around that puts this bias into (historical) perspective. Humans – who are willing to adjust for their biases – can do this, but it requires connecting very different types of information they learn through observation but even more likely through reading and debating with others.
So far, we can only address some obvious biases in AI system. We can’t build AIs that can do adjust for their built-in biases based on other knowledge. Until we figure out how to do that -– if we ever do – we need to continue to question their responses and detect the influence of those many other biases ourselves.